Sparse, Secure Gradient Agrregation
in Study Log on Algorithm, Concurrent Programming, Federated-learning
Sparse, Secure Gradient Aggregation is a method in Federated learning.
The method uses sparse gradient in combination with secure multi-party-computation to ensure gradients can not be converted to the original data.
Wait-free Bounded Queue Source Code
#include <atomic>
#include <chrono>
#include <cinttypes>
#include <cstdio>
#include <thread>
using namespace std;
#define NUM_PRODUCER 4
#define NUM_CONSUMER NUM_PRODUCER
#define NUM_THREADS (NUM_PRODUCER + NUM_CONSUMER)
#define NUM_ENQUEUE_PER_PRODUCER 10000000
#define NUM_DEQUEUE_PER_CONSUMER NUM_ENQUEUE_PER_PRODUCER
#define QUEUE_SIZE 1024
typedef struct QueueNode {
int key;
uint64_t flag;
} QueueNode;
class Queue {
private:
struct QueueNode *slot;
uint64_t size;
atomic<uint64_t> front;
atomic<uint64_t> rear;
public:
Queue(uint64_t _size) : slot(new QueueNode[_size]), size(_size), front(0), rear(0) {}
void enqueue(int key) {
uint64_t cur_slot = rear++;
int order = cur_slot / size;
cur_slot = cur_slot % size;
while (true) {
uint64_t flag = slot[cur_slot].flag;
if (flag % 2 == 1 || flag / 2 != order) {
this_thread::yield();
} else {
slot[cur_slot].key = key;
slot[cur_slot].flag++;
break;
}
}
}
int dequeue() {
uint64_t cur_slot = front++;
int order = cur_slot / size;
cur_slot = cur_slot % size;
while (true) {
uint64_t flag = slot[cur_slot].flag;
if (flag % 2 == 0 || flag / 2 != order) {
//if (slot[cur_slot].flag % 2 == 0 || slot[cur_slot].flag / 2 != order) {
this_thread::yield();
} else {
int ret = slot[cur_slot].key;
slot[cur_slot].flag++;
return ret;
}
}
}
~Queue() {
delete[] slot;
}
};
bool flag_verification[NUM_PRODUCER * NUM_ENQUEUE_PER_PRODUCER];
Queue queue(QUEUE_SIZE);
void ProducerFunc(int tid) {
int key_enqueue = NUM_ENQUEUE_PER_PRODUCER * tid;
for (int i = 0; i < NUM_ENQUEUE_PER_PRODUCER; i++) {
queue.enqueue(key_enqueue);
key_enqueue++;
}
return;
}
void ConsumerFunc() {
for (int i = 0; i < NUM_DEQUEUE_PER_CONSUMER; i++) {
int key_dequeue = queue.dequeue();
flag_verification[key_dequeue] = true;
}
return;
}
int main(void) {
std::thread threads[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; i++) {
if (i < NUM_PRODUCER) {
threads[i] = std::thread(ProducerFunc, i);
} else {
threads[i] = std::thread(ConsumerFunc);
}
}
for (int i = 0; i < NUM_THREADS; i++) {
threads[i].join();
}
// verify
for (int i = 0; i < NUM_PRODUCER * NUM_ENQUEUE_PER_PRODUCER; i++) {
if (flag_verification[i] == false) {
printf("INCORRECT!\n");
return 0;
}
}
printf("CORRECT!\n");
return 0;
}
Possible Infinite Loop Situation
작성한 키노트가 있기에 키노트 이미지들로 설명을 대체 합니다. jpeg 파일 보기

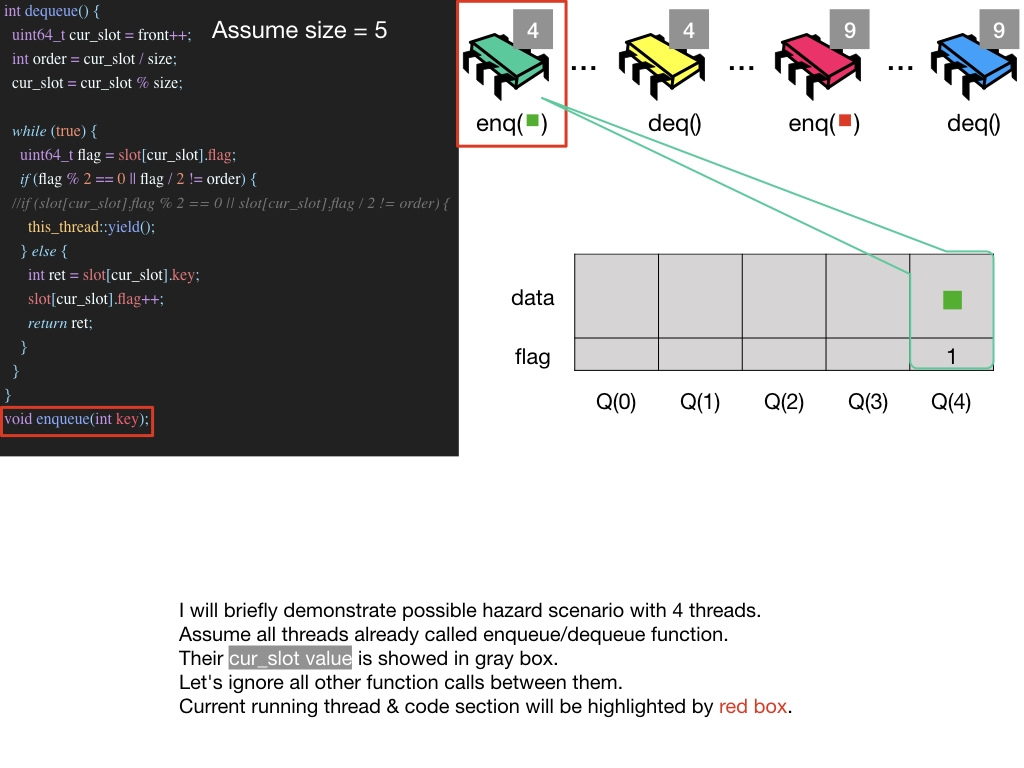

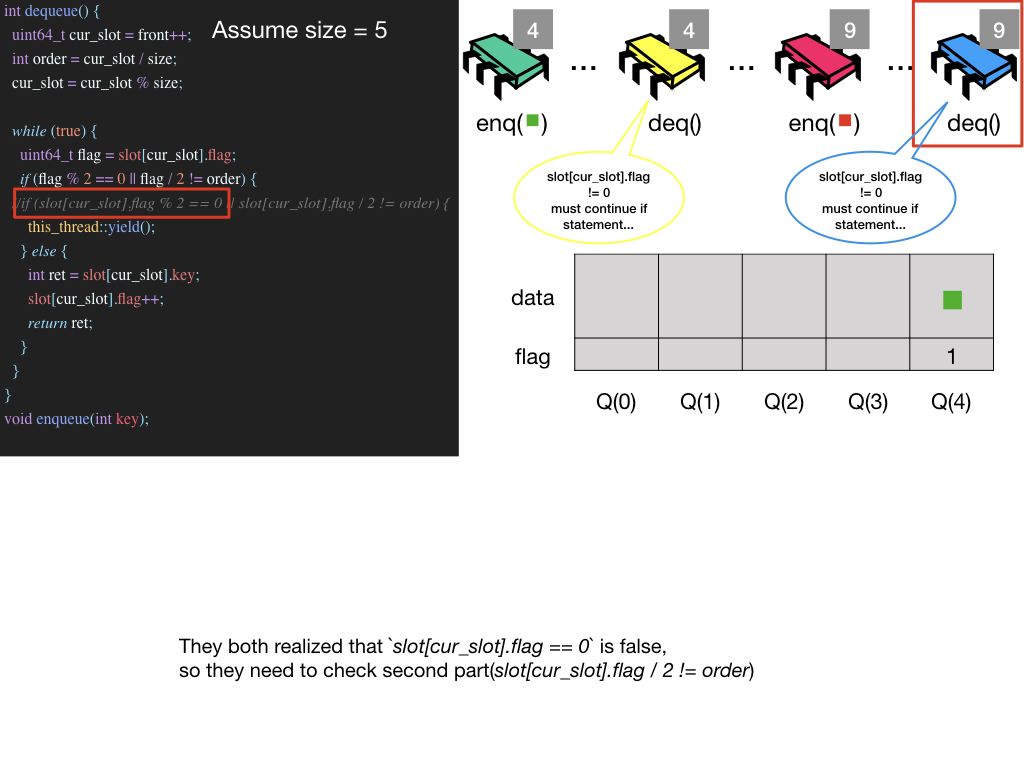
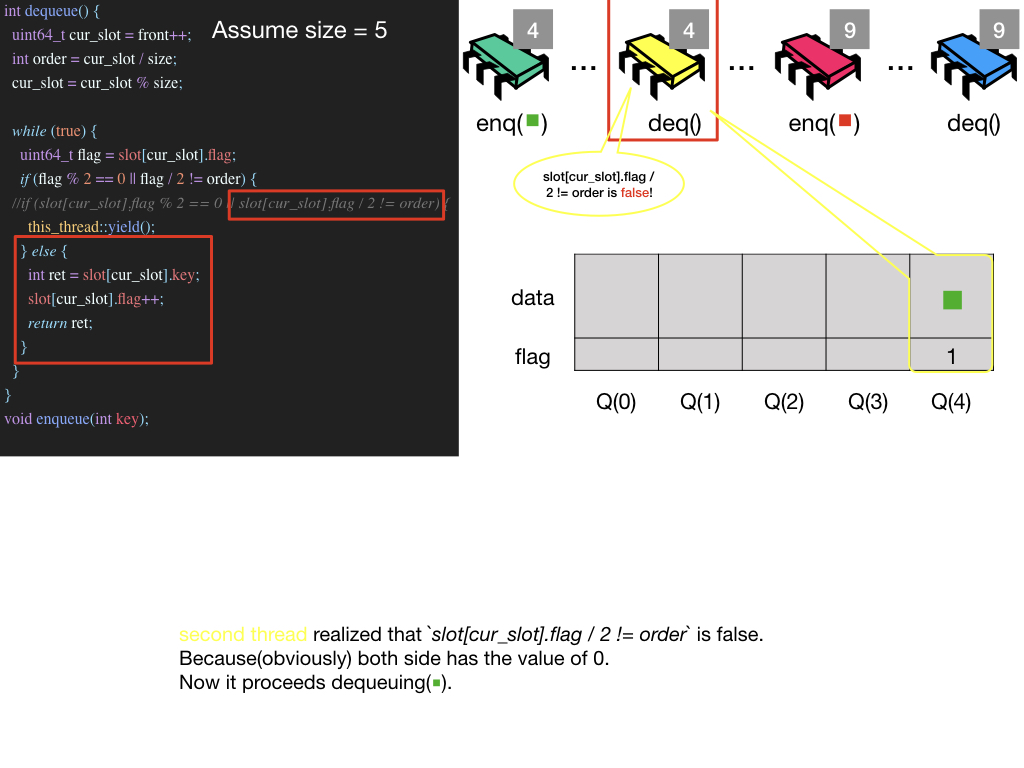
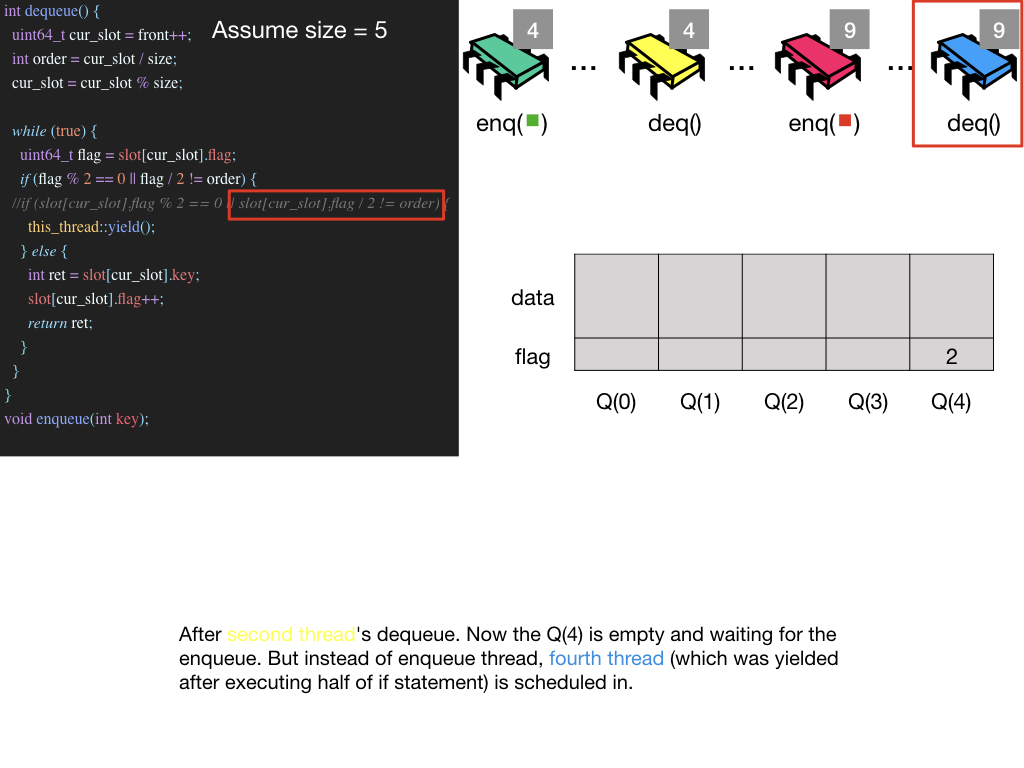
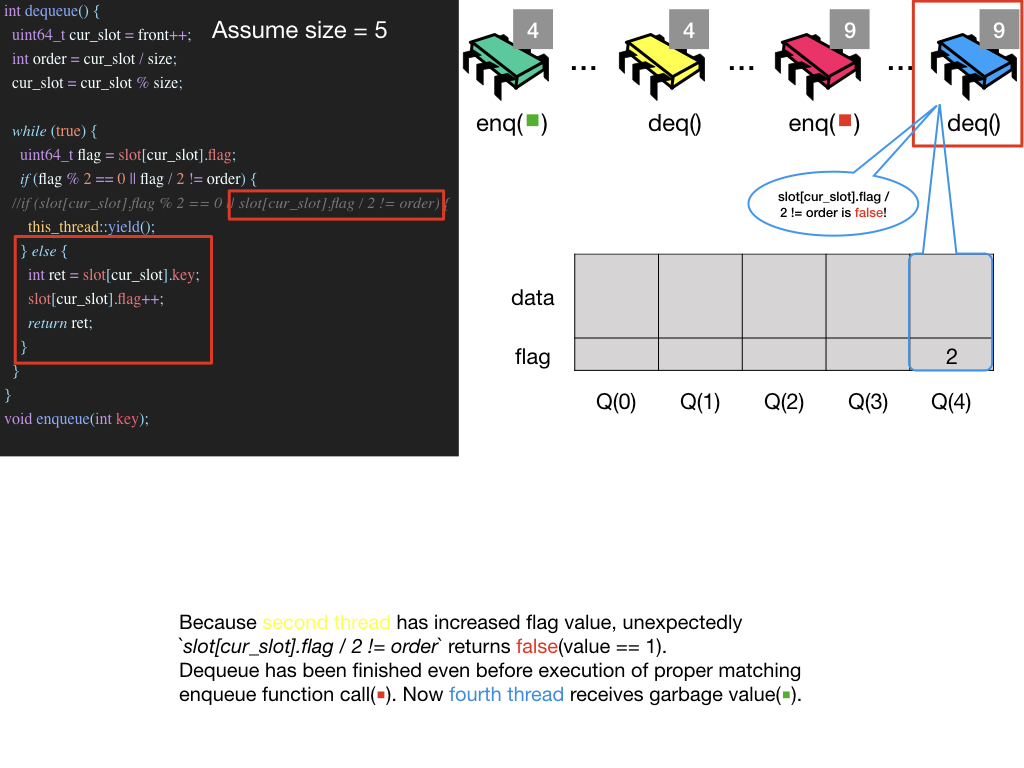
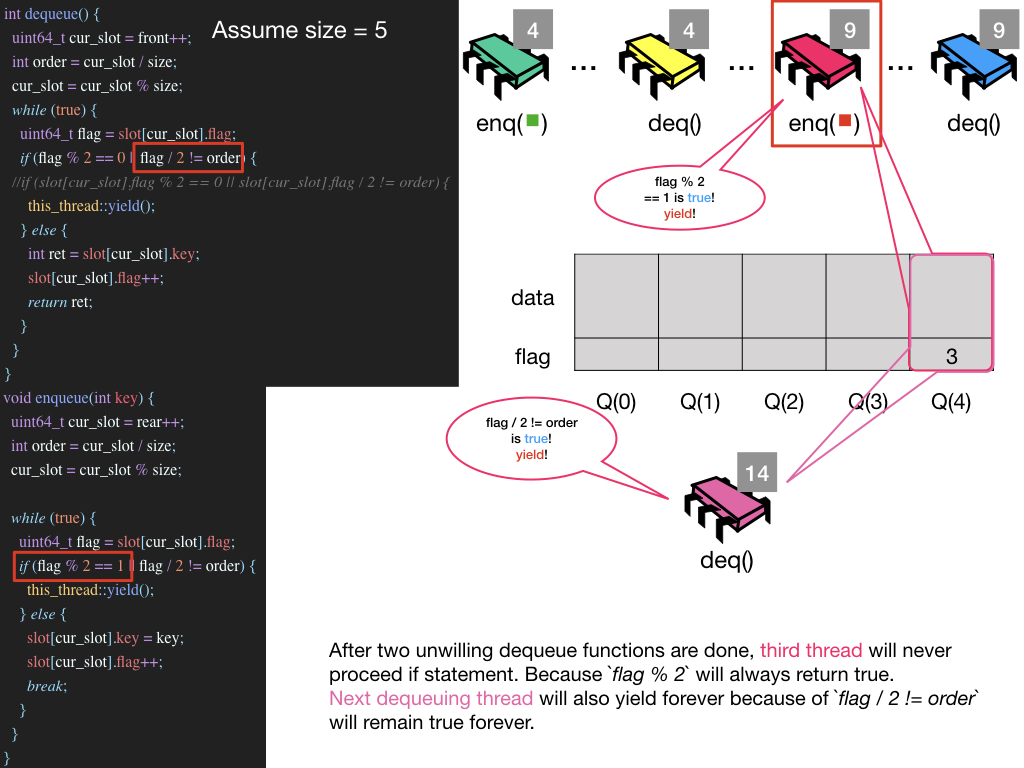
p.s. 블로그 내의 모든 keynote들은 Github Page에서 확인할 수 있습니다.(keynote 주의!)
